C++에는 이렇게 많은 키워드가 있다. C++은 C에서 처음 시작했지만 시대가 발전하면서 Python, Haskell 등 프로그래밍의 패러다임을 바꾼 수많은 언어가 튀어나왔고 C++는 30년 동안 그 수많은 패러다임을 다 먹어치울 기세로 커졌기 때문이다. 그 과정에서 C++의 몇몇 키워드는 의미가 바뀌기도 했다. 가장 대표적인 키워드가 inline으로, 이 키워드는 C++에서 함수 실행 오버헤드를 줄이기 위해 함수 호출하는 부분을 그냥 함수 본문으로 대체하는 것과는 전혀 관련이 없다. 모든 C++ 개발자들은 바뀐 키워드의 내용을 숙지하여 모던한 프로그래밍 습관을 기르도록 하자.


auto
(C에서) storage duration을 auto로 설정함
(C++11부터) 정의된 변수의 타입을 컴파일러가 알아서 추론하도록 설정함
C에서 storage duration specifier은 auto, register, static, extern 이렇게 4개가 있었는데, 그중에서도 auto는 유독 존재감이 없었다. storage duration specifier을 적어주지 않으면 어차피 auto로 설정되기 때문(...)이었다. 이것이 정말 개 쓸데없는 키워드였으므로 auto라는 키워드는 C++ 역사상 처음으로 뜻이 바뀌는 영광을 안게 된다.
C에서 타입 이름을 적어주는 것은 그렇게 어렵지는 않은 일이었다. 길어 봤자 long long 같은 이름이기 때문이다. 나는 옛날에는 long long 같은 이름도 치기 귀찮아서 #define ll long long 같은 짓거리를 일삼았지만... 하지만 C++의 강력한 템플릿 기능 덕분에 사람들은 갈수록 다음과 같은 끔찍한 타입 이름들을 만나게 되었다.
__gnu_cxx::__alloc_traits<std::allocator<char>, char>::value_type&정말 말도 안 되게 길지만 이것은 std::string을 쓰다 보면 자주 만나게 되는 타입 이름으로, aka 'char&'이다. 다행히도 이것은 C++ 타입 이름의 끔찍함을 보여주기 위한 극단적 예시일 뿐이며, 이런 이름은 컴파일러의 에러 메시지를 읽을 때나 볼 수 있다. 하지만 이것보다 끔찍하진 않지만 충분히 귀찮은 예시가 C++에 널려 있다. 예를 들어, C에서 배열 순회를 다음과 같이 한다.
int arr[69];
int *p;
for (p = arr; p < arr + 69; ++p) {
*p += 1;
}C++에서는 벡터 순회를 다음과 같이 한다.
std::vector<int> v(69);
for (std::vector<int>::iterator it = v.begin(); it != v.end(); ++it) {
*it += 1;
}C에서 int *가 했던 일을 C++에서는 저렇게 긴 타입 이름을 가진 무언가가 대신한다니 참 끔찍하다고 할 수 있다. 다행히, C++ 개발자들은 컴파일러가 v.begin()의 타입을 알고 있다면, it의 타입 이름을 굳이 프로그래머가 명시하지 않아도 컴파일러가 알아서 추론할 수 있음을 발견했다. 따라서 이를 구현하기 위해 타입을 지정하지는 않되 변수임을 알려주기는 하는 어떤 키워드가 필요했으며, 결국 버려진 키워드나 마찬가지였던 auto가 이 일을 맡게 되었다.

class
(C++에서) 클래스를 선언함
(C++11에서 기능 추가) enum class를 선언함
개발자가 다루는 프로그램의 크기가 점점 커지면서 개발자들은 수많은 이름이 프로그램을 더럽혀 가는 것을 해결할 방법을 찾아야 했다. 예를 들어 내가 hello() 함수를 정의했는데, 다른 라이브러리를 갖고 와 보니까 그 라이브러리에서도 hello() 이름을 쓰고 있다거나... C++의 namespace는 이 문제를 해결하기 위해 도입된 방법 중 하나였다.
enumeration이라는 기능은 편리하긴 하지만 수많은 이름을 만들어 프로그램을 더럽히기도 한다. 예를 들어,
enum Yoil {MON, TUE, WED, THU, FRI, SAT, SUN};이 코드는 어떤 namespace에도 속하지 않은 갈 곳 없는 이름을 7개나 만들어낸다. enum class는 이 문제를 해결하기 위해 등장하였다. enum class로 선언된 enum들은 반드시 그 클래스 이름과 함께 불려야 한다.
enum class Yoil {MON, TUE, WED, THU, FRI, SAT, SUN};
MON != TUE // invalid
Yoil::MON != Yoil::TUE // valid

default
(C에서) switch문의 default case를 선언함
(C++11에서 기능 추가) special member function을 컴파일러가 제공하는 기본값으로 설정함
(C++20에서 기능 추가) 비교 연산자(<, >, ==)를 컴파일러가 제공하는 기본값으로 설정함
special member function은 다음 6종류의 멤버 함수를 말한다.
생성자 / 복사 생성자 / 이동 생성자 / 복사 대입 연산자(=) / 이동 대입 연산자(=) / 소멸자
생성자를 예로 들면, 모든 클래스가 꼭 사용자 정의 생성자를 가질 필요는 없다. F라는 클래스가 멤버 a, b라는 변수를 갖고 있으면 그냥 a의 디폴트 생성자와 b의 디폴트 생성자를 부르는 것이 가장 자연스러운 구현일 수도 있다. 따라서 C++에는 옛날부터, 생성자를 생략하면 컴파일러가 이런 생성자를 알아서 만들어 주는 기능이 있었다. 다만 이렇게 하면 생성자를 빼놓은 것이 의도인지, 아니면 그냥 만들다 만 거라서 그런 건지 개발자들 사이에서도 헷갈렸던 모양이다. 생성자를 = default; 로 선언해 주면 컴파일러가 자동으로 제공하는 디폴트 생성자를 쓴다는 사실을 명시적으로 보여줄 수 있다.
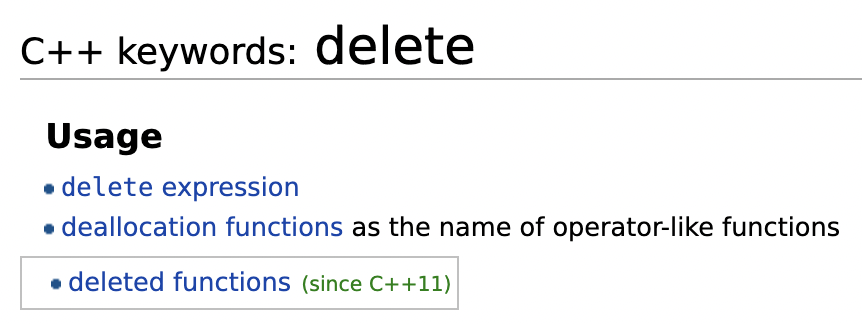
delete
(C++에서) 힙 메모리 할당을 해제함
(C++11부터 기능 추가) 컴파일러가 자동으로 만들어주는 함수를 삭제함
아마도 이 기능은 std::unique_ptr을 구현하기 위해 만들어진 것으로 보인다. std::unique_ptr은 new 연산자를 통해 동적 할당받은 영역에 대한 소유권을 '유일하게' 갖는 포인터이며, std::unique_ptr의 소멸자가 호출되는 순간 할당받은 영역도 자동으로 free가 된다. 따라서 개발자가 메모리 해제를 일일이 해 주지 않아도 자동으로 메모리 누수를 막아주는 "스마트 포인터"이다. (사실은 포인터가 아니라 포인터의 대리자(Proxy)지만 그런 것까지 신경쓰지는 말도록 하자.)
RAII라는 개념이 발명되고 스마트 포인터라는 아이디어가 제시되고 나서 메모리 관리가 편해졌다. 문제는 std::unique_ptr가 정말로 소유권을 유일하게 갖는지가 확실치 않다는 것이었다. std::unique_ptr도 복사 생성자를 갖고 있기 때문에, 복사를 하기만 해도 같은 공간에 대한 소유권을 갖는 포인터가 2개가 되는 것 아닌가? 이것을 막기 위해 C++11에서는 std::unique_ptr의 복사 생성자를 그냥 지워버린다. 이를 구현하기 위해 delete에 새로운 기능이 추가되었다.
delete는 또한 자동 타입 변환을 막아주는 재미있는 기능도 가지고 있다.
int add_1(int n) {
return n + 1;
}
int add_1(long long n) = delete;
add_1(7LL) // ERROR! 이제 long long이 int로 자동 형변환되지 않음
inline
인라인 함수를 정의함
(C++17부터) 인라인 변수를 정의함
inline이란 키워드를 C에서 처음 접했다면 '인라인 함수는 알겠는데 대체 인라인 변수가 뭐지?? 인라인 함수는 치환을 통해 함수 호출 오버헤드를 줄이는 거였는데 그게 변수에 적용된다는 게 말이 되나?' 하고 생각할 수 있다. 이것은 모두 언젠가부터 인라인 함수의 정의가 바뀐 탓이다. 모던 C++에서 inline은 치환을 통해 함수 호출 오버헤드를 줄이는 것과는 별 상관이 없다. 언제부터 그렇게 됐는가는 C++ 공식 문서에 안 나와 있어서 잘 모르겠지만, 아무튼 그렇다. (C에서 inline이 도입된 게 1999년이었고 C++11 이전의 최근 C++ 버전은 C++98이었다. 어쩌면 C에서의 inline과 C++에서의 inline은 아무런 관련이 없을 수도 있다)
사실 C에서도 inline이라는 키워드는 컴파일러에게 제공하는 힌트 비슷한 것이었다. 따라서 C에서 inline으로 선언된 함수가 사용되었을 때 꼭 치환되지는 않는다. 예를 들어 1000줄(...)짜리 함수에 inline을 썼다고 그 함수가 1000줄짜리 코드로 치환되지는 않는다. 컴파일 과정에서의 코드 최적화에 대한 이론이 발전하면서, 컴파일러는 함수 크기가 얼마나 작아야 치환을 통해 함수 호출 오버헤드를 줄이는 것이 이득인지, 얼마나 커야 이득이 아닌지를 스스로 판단할 수 있게 되었다. 따라서 프로그래머가 직접 이걸 명시하는 게 아무 의미도 없게 되었다. 이것은 비슷하게 최적화 관련 키워드였던 register도 마찬가지. 나중에 소개할 register는 이 때문에 키워드 자체가 아무 의미 없어져 버린다.
C++에서 inline이란, 전체 프로그램에서 여러 군데에 정의되어 있어도 된다는 뜻이다. 단 전체 프로그램을 말하는 거지 하나의 translation unit에서는 정의가 하나만 존재해야 한다. C++17부터, 여러 군데에 정의된 inline 함수의 정의는 동일해야 한다. 마찬가지로 inline variable 또한 전체 프로그램에서 여러 군데에 정의될 수 있는 변수를 말한다.
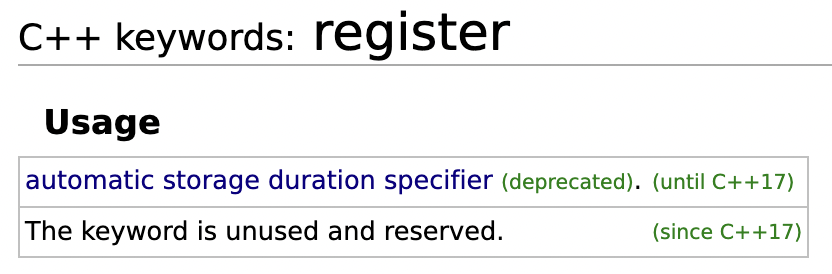
register
(C에서) 변수를 선언하면서 웬만하면 이 친구를 레지스터 영역에 넣어달라고 간청함
(C++17부터) 아무 효과 없음
register 키워드는 본래 최적화와 관련 있다. 레지스터 영역에 저장된 변수는 더 빠르게 접근이 가능하기 때문이다. register 키워드가 아무 의미 없어진 것은 inline 키워드가 더 이상 C에서 얘기하는 그 인라인 함수와 관련없어진 것과 비슷하다. "어차피 컴파일러가 다 최적화해 주니까 인간들은 코딩이나 하셈"이란 뜻.

using
(C++에서) 한 네임스페이스 내부의 요소 일부 또는 전부를 다른 네임스페이스로 가져옴
(C++에서) 상속받을 때 부모 클래스의 멤버 변수 또는 멤버 함수를 수정 없이 그대로 사용함
(C++11에서 기능 추가) 타입 별칭과 타입 별칭 템플릿 선언
C 스타일 타입 별칭 선언 방식인 typedef는 두 가지 문제점이 있었다. 첫 번째 문제점은 읽기 어렵다는 것이다.
typedef std::vector<std::vector<int>>::iterator vvii;보면 알겠지만 이 문제점은 C++에서 타입 이름이 갈수록 길어지면서 두드러진 문제점이기도 하다.
우리가 만약 변수 x에 대한 정보를 알고 싶다면, x의 선언부에 가야 한다. 이때 선언부는 다음과 같이 생겼을 것이다.
int x = 417 * 717 + 110 / 417 + 717 * 110;이 선언은 우리가 글을 쓸 때 무언가를 정의하는 방법과 비슷하다. 예컨대 "x는 2의 23제곱에 119를 곱하고 1을 더한 것이다". 그런데 유독 typedef문만 이 convention과 사용법이 반대다. 따라서 이 문제를 해결할 수 있도록 다음과 같이 using문을 도입하기로 했다.
using vvii = std::vector<std::vector<int>>::iterator;typedef문의 2번째 문제점은 템플릿화가 불가능하다는 것이다. using문에서는 멀쩡하게 템플릿을 이용할 수 있다.
template <typename T>
typedef std::vector<std::vector<T>> vector2d; // invalid
template <typename T>
using vector2d = std::vector<std::vector<T>>; // valid'Computer Science > C++' 카테고리의 다른 글
| 충격!) C++에서 Rust의 블록 표현식과 유사한 구문을 사용할 수 있다?! (0) | 2024.03.04 |
|---|---|
| [C++] 객체지향, 제네릭 세그먼트 트리 라이브러리 구현하기 (0) | 2023.10.03 |
| [C++] TMP로 컨테이너 내부 타입 정보 얻어오기 [템플릿 메타프로그래밍] (0) | 2022.10.22 |
| [C++] 프록시(Proxy) 디자인 패턴 (feat. bitset) (0) | 2022.09.18 |
| C++ Dynamic Programming 꿀팁 (0) | 2022.08.23 |

댓글